AI today: Data, training and inferencing
In my last blog, I discussed artificial intelligence, machine learning and deep learning and some of the terms used when discussing them. Today, I’ll focus on how data, training and inferencing are key aspects to those solutions.
The large amounts of data available to organizations today have made possible many AI capabilities that once seemed like science fiction. In the IT industry, we’ve been talking for years about “big data” and the challenges businesses face in figuring out how to process and use all of their data. Most of it — around 80 percent — is unstructured, so traditional algorithms are not capable of analyzing it.
A few decades ago, researchers came up with neural networks, the deep learning algorithms that can unveil insights from data, sometimes insights we could never imagine. (To understand the basic definition of deep learning, check out my previous post.) If we can run those algorithms in a feasible time frame, they can be used to analyze our data and uncover patterns in it, which might in turn aid in business decisions. These algorithms, however, are compute intensive.
Training neural networks
A deep learning algorithm is one that uses a neural network to solve a particular problem. A neural network is a type of AI algorithm that takes an input, has this input go through its network of neurons — called layers — and provides an output. The more layers of neurons it has, the deeper the network is. If the output is right, great. If the output is wrong, the algorithm learns it was wrong and “adapts” its neuron connections in such a way that, hopefully, the next time you provide that particular input it gives you the right answer.
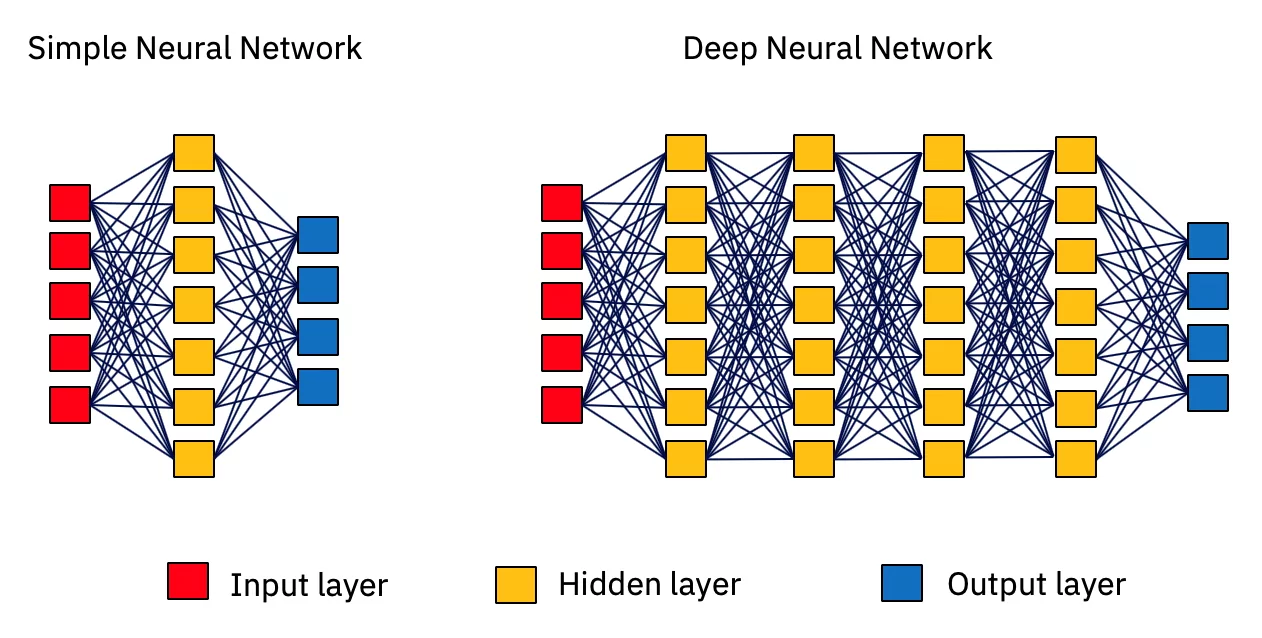
Fig 1: Illustration of computer neural networks
This ability to retrain a neural network until it learns how to give you the right answer is an important aspect of cognitive computing. Neural networks learn from data they’re exposed to and rearrange the connection between the neurons.
The connections between the neurons is another important aspect, and the strength of the connection between neurons can vary (that is, their bond can be strong, weak or anywhere in between). So, when a neural network adapts itself, it’s really adjusting the strength of the connections among its neurons, so that next time it can provide a more accurate answer. To get a neural network to provide a good answer to a problem, these connections need to be adjusted by exhaustively exercising repeated training of the network — that is, exposing it to data. There can be zillions of neurons involved, and adjusting their connections is a compute-intensive matrix-based mathematical procedure.
We need data and compute power
Most organizations today, as we discussed, have tons of data that can be used to train these neural networks. But there’s still the problem of all of the massive and intensive math required to calculate the neuron connections during training. As powerful as today’s processors are, they can only perform so many math operations per second. A neural network with a zillion neurons trained over thousands of training iterations will still require a zillion thousand operations to be calculated. So now what?
Thanks to the advancements in industry (and I personally like to think that the gaming industry played a major role here), there’s a piece of hardware that’s excellent at handling matrix-based operations called the Graphics Processing Unit (GPU). GPUs can calculate virtually zillions of pixels in matrix-like operations in order to show high-quality graphics on a screen. And, as it turns out, the GPU can work on neural network math operations in the same way.
Please, allow me to introduce our top math student in the class: the GPU!

Fig 2: An NVIDIA SMX2 GPU module
A GPU is a piece of hardware capable of performing math computations over a huge amount of data at the same time. It’s not as fast as a central processing unit (CPU), but if one gives it a ton of data to process, it does so massively in parallel and, even though each operation runs more slowly, the parallelism of applying math operations to more data at once beats the CPU performance by far, allowing you to get your answers faster.
Big data and the GPU have provided the breakthroughs we needed to put neural networks to good practice. And that brings us to where we are with AI today. Organizations can now apply this combination to their business and uncover insights from their vast universe of data by training a neural network for that.
To successfully apply AI in your business, the first step is to make sure you have lots of data. A neural network performs poorly if trained with little data or with inadequate data. The second step is to prepare the data. If you’re creating a model capable of detecting malfunctioning insulators in power lines, you must provide it data about working ones and all types of malfunctioning ones. The third step is to train a neural network, which requires lots of computation power. Then after you train a neural network and it performs satisfactorily, it can be put to production to do inferencing.
Inferencing
Inferencing is the term that describes the act of using a neural network to provide insights after is has been trained. Think of it like someone who’s studying something (being trained) and then, after graduation, goes to work in a real-world scenario (inferencing). It takes years of study to become a doctor, just as like it takes lots of processing power to train a neural network. But doctors don’t take years to perform a surgery on a patient, and, likewise, neural networks take sub-seconds to provide an answer given real world data. This happens because the inferencing phase of a neural network-based solution doesn’t require much processing power. It requires only a fraction of the processing power needed for training. As a consequence, you don’t need a powerful piece of hardware to put a trained neural network to production, but you could use a more modest server, called an inference server, whose only purpose is to execute a trained AI model.
What the AI lifecycle looks like:
Deep learning projects have a peculiar lifecycle because of the way the training process works.
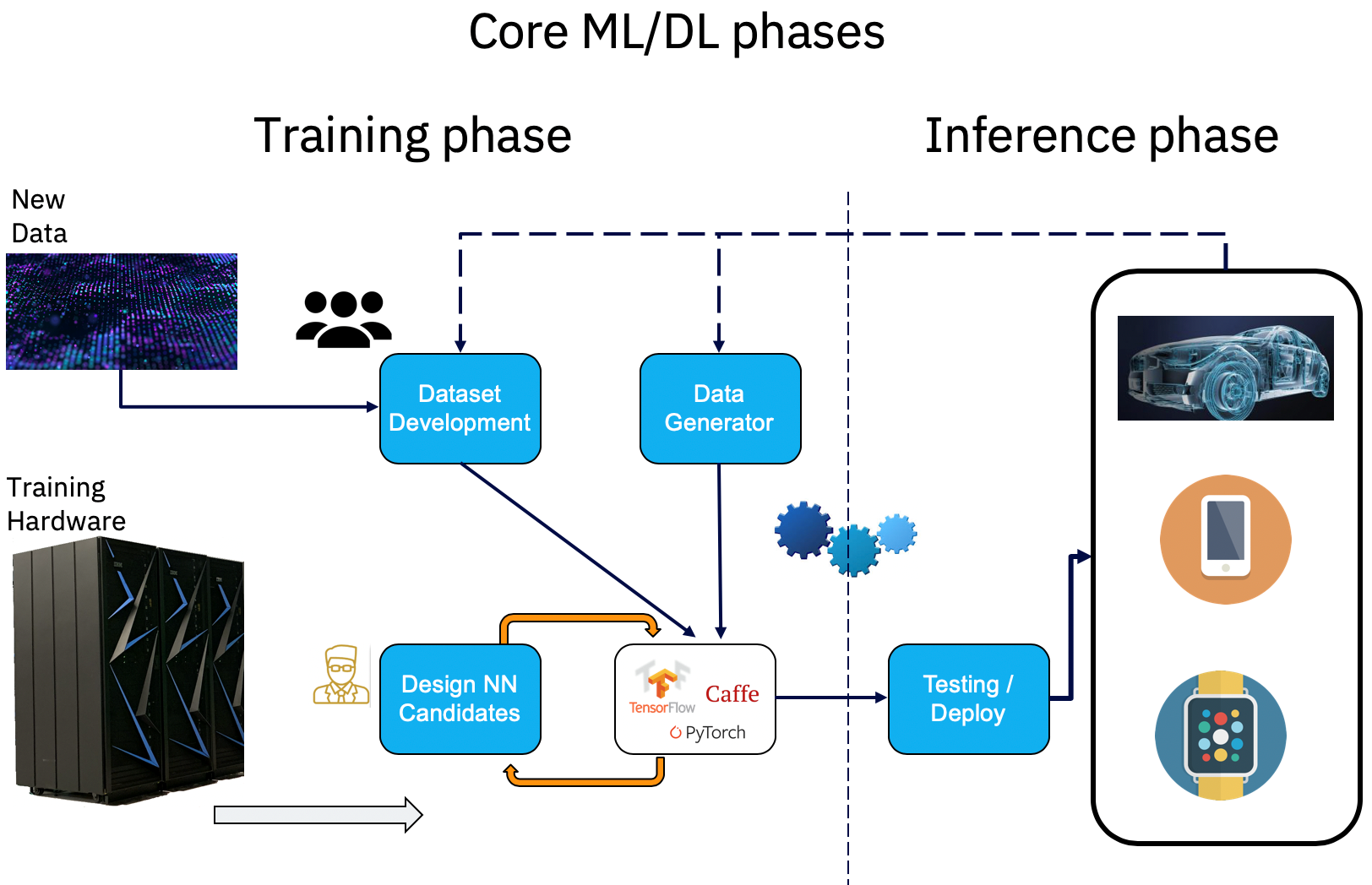
Fig 3: A deep learning project’s lifecycle
Organizations these days are facing the challenge of how to apply deep learning to analyzing their data and obtaining insights from it. They need to have enough data to train a neural network model. That data has to be representative to the problem they’re trying to solve; otherwise the results won’t be accurate. And they need a robust IT infrastructure made up of GPU-rich clusters of servers to train their AI models on. The training phase may go on for several iterations until the results are satisfactory and accurate. Once that happens, the trained neural network is put to production on much less powerful hardware. The data processed during the inferencing phase can retro feed the neural network model to correct it or enhance it according to the latest trends being created in newly acquired data. Therefore, this process of training and retraining happens iteratively over time. A neural network that’s never retrained will age over time and potentially become inaccurate with new data.
This post offers a high-level view of how data, training and inferencing are all key aspects of deep learning solutions. There’s a lot more to be said about the hardware, software and services that can help businesses achieve successful AI implementations, and in upcoming articles I’ll take a deeper dive into each area. Wherever you are on the AI journey with IBM Power Systems, IBM Systems Lab Services has experienced consultants who can help. Contact us today.
The post AI today: Data, training and inferencing appeared first on IBM IT Infrastructure Blog.